 |
(a) Internet Explorer Ver.8 |
 |
(b) Mozilla Firefox Ver.3.63 (縮小表示) |
| 図2.1 sample1.xml の WEBブラウザでの表示例(1) | |
前回は、簡単なXMLを書きました。ただし、実際にはより複雑な構造のデータを取り扱うことが多くなるでしょう。XMLは厳密な構文であり、書き方を誤ることもあるでしょう。そこで、今回は、XML文書を作成する上での留意点として、構文の意味を学習します。
前回のまとめにおいて、「<?xml version = "1.0" encoding = "Shift_JIS"?> は、XML文書として認識されるために、1行目に必須の構文」であると述べました。1行目の構文には、どのような意味があるでしょう。
XMLは、テキスト・ファイルです。テキスト・ファイルとして示されるものは XML の他にも、プレーンテキストやHTMLなど様々あります。XML文書として作成したテキスト・ファイルを、XML文書としてコンピュータに処理させるには、他のテキスト・ファイルと区別しなくてはなりません。その区別の手段は以下の2つを同時に満たすことです。
ここで、<?xml version = "xxx"?> を「XML宣言」、XML文書を処理するソフトを「XMLパーサー」と言います。
拡張子が「.xml」である時点でXML文書と区別できそうなものですが、話はそう単純ではありません。XMLパーサーがXML文書以外のファイルに対応する場合が考えられます。例えば、WEBブラウザはHTMLファイルとXMLファイルを処理できますが、それぞれの処理方法が異なるためXML宣言による区別が必要です。
そして、XMLの規格は進化しています。2010年現在、XMLには 1.0 と 1.1 の2つのバージョンがあり、新たに 2.0 を策定するための議論も行われています。しかも、XMLが広まるに伴って、様々な要求に応えるために改定が行われています。バージョン 1.1 が策定されたことでバージョン 1.0 が消滅したわけではありません。バージョン 1.0 は 2008年11月26日 に改定されており、今でも現役です。XML宣言のバージョン表記によって、XMLパーサーが異なるバージョンのXMLを適切に処理できるようになります。
「version = "xxx"」に続く「encoding = "xxx"」の部分は「文字エンコーディング・スキーム」と呼ばれ、XML文書の文字コードを記述します。コンピュータ上で文字を利用するために各文字に割り当てられる情報(文字コード)は、処理系によって異なるので、文字エンコーディング・スキームで区別する必要があります。
文字エンコーディング・スキームで指定できる文字コードを以下に示します。
| 表3.1 文字エンコーディング・スキームで指定できる文字コード | ||||||||||||||||||
|
XMLは多言語環境の対応を前提とした仕様であり、サポートすべき文字コードを ISO-8859-X (Unicode)のみと定めています。また、この仕様は他の文字コードの使用を禁止するものではありません。前章のサンプルは Windows のメモ帳で作成することを前提とし、メモ帳が唯一対応するシフトJISコードで作成しましたが、表示上の問題は起こりませんでした。ただし、ソフトウェアが文字コードをUnicodeに変換することによって問題を回避しているため、変換機能のないソフトウェアでは文字化けなどの問題が起こることがあります。
※以降、サンプルは文字コードをUTF-8として提示します。UTF-8対応のテキスト・エディタで編集し UTF-8形式でファイルを保存するか、継続して Windows のメモ帳をするならば文字エンコーディング・スキームを「encoding = "Shift_JIS"」と書き換えてください。
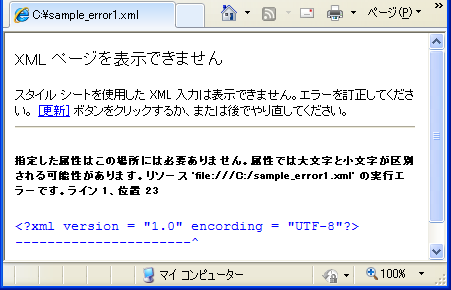
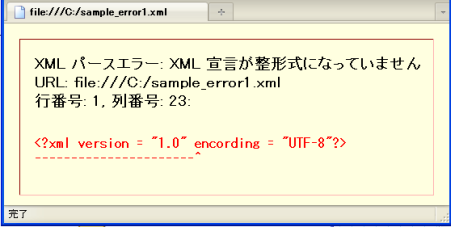
「XMLの構文が厳密である」とは、わずかな誤りでもXMLパーサーがエラーを返し処理をやめるということです。HTML文書に対して、WEBブラウザがウェブページの意図を推測しレンダリングを実行するのとは対照的です。以下に、文字エンコーディングスキームのつづりを1文字だけ誤った("encording")XMLを示します。
| 表3.1 sample_error1.xml - XML宣言内のつづりの誤り |
<?xml version = "1.0" encording = "UTF-8"?> <サンプル> <タイトル>sample_error1.xml</タイトル> <本文>構文エラーの例</本文> </サンプル> |
表3.1のXML文書を WEBブラウザで表示しようとすると、以下の図のようにエラーを返します。"encording" がエラーであることを示しています。
|
(a) Internet Explorer Ver.8 |
|
(b) Mozilla Firefox Ver.3.63 (縮小表示) |
| 図2.1 sample1.xml の WEBブラウザでの表示例(1) | |
以下に他の構文エラーの例を挙げながら、XMLの基礎的な構文を学習します。
以下の例は終了タグが無いためにエラーを返します。他の要素の開始タグを以て終了タグを兼ねたり、HTMLのように終了タグが不要な要素は定められていません。
| 表3.2 sample_error2.xml - 終了タグが無い |
<?xml version = "1.0" encoding = "UTF-8"?> <サンプル> <タイトル>sample_error2.xml <本文>終了タグが無い </サンプル> |
1つの要素名に対しては、必ず開始タグと終了タグの組を必要とします。アルファベットの場合、大文字と小文字は区別されます。よって <ABC> ... </abc> のような書き方はエラーを返します。この場合、XMLパーサーは、<ABC>に対する終了タグが無く、</abc>に対する開始タグが無いと解釈します。
以下のように、開始タグと終了タグの間に何も書かれてなくても問題はありません。
<element></element>
このような要素を「空要素」といいます。空要素は以下のように簡略して記述することができます。
<element/> 、または要素名と '/' の間にスペースを追加した <element />
要素名と '/' の間にスペースを追加することには、古いWEBブラウザと互換を保つための意味がありますが、ここでは割愛します。なお、空要素において、'/' と '>' の間には、スペースを含めいかなる文字も記述してはならないことになっています。また、空要素タグは以下のように属性(オプション)を設定することができます。
<element option1 = "属性値1" option2 = "属性値2"/>
ただし、オプション名とその属性は、タグ同様ユーザーが設定する必要があります。属性値は全てシングルクォート (') またはダブルクォート (") のいずれかで括ります。
XML文書で最初に出現する要素を「ルート要素」といいます。ルート要素は1つのXML文書で唯一の存在でなくてはなりません。以下の例はルート要素と同じ要素名が出現するためにエラーを返します。
| 表3.3 sample_error3.xml - ルート要素の重複:青字が「ルート要素」 |
<?xml version = "1.0" encoding = "UTF-8"?> <サンプル> <タイトル>sample_error3.xml</タイトル> <サンプル>ルート要素と同じ要素名</サンプル> <本文>ルート要素の重複</本文> </サンプル> |
ルート要素以外であれば複数の要素が出現しても問題はありません。また、要素「xxx」の構成要素として上位要素と同じ要素名を使うこともできます。以下に例を示します。
| 表3.4 sample_nest.xml - 同じ要素名の要素を含む例 |
<?xml version = "1.0" encoding = "UTF-8"?> <サンプル> <タイトル>sample_nest.xml <タイトル>要素名の重複-同じ要素名による階層構造</タイトル> </タイトル> <本文>この文書は正しい構文で書かれています。 <タイトル>ルート要素でなければ要素名が複数出現しても問題はありません</タイトル> </本文> </サンプル> |
ルート要素を除き、ある要素はその上位の要素に完全に「含まれて」いなければなりません。即ち、タグは入れ子構造であることが必要です。以下の例は要素が入れ子構造(データ構造が階層型・包含関係)ではない例です。このXML文書は「用語」と「注釈」の上位/下位関係が不明確であるためにエラーを返します。
| 表3.5 sample_error4.xml - 階層型構造ではない |
<?xml version = "1.0" encoding = "UTF-8"?> <サンプル> <タイトル>sample_error4.xml</タイトル> <本文> <見出し>階層型構造ではない</見出し> <パラグラフ>要素「用語」と要素「注釈」は重なっています</パラグラフ> <用語>パラグラフ:ある一つのトピックについて述べた文の集まり <注釈>一文の場合もある…日本語の「段落」に近いが、完全に同じ概念ではない </用語> </注釈> </本文> </サンプル> |
「整形式XML文書 (well-formed XML document)」とは、XMLの構文規則のすべてに準拠して書かれたXML文書を指します。「整形式」とは「整形-式…様式」ではなく「整-形式…形式が整っている」ことを意味します。XMLパーサーがエラーを返さずに処理できるXML文書は、整形式XML文書といえます。
このほか、整形式XML文書であることに加えて、文書の論理的構造規定に準拠しているXML文書を「妥当なXML文書 (valid XML document)」といいます。妥当なXML文書については後述します。
本章では、XML文書を作成する上での留意点として、構文の意味を学習しました。整形式XML文書を書くには、本章までの内容に留意することが必要ですが、まだデータ構造の表現にとどまっており、多様な文書の表現には至りません。今後はXML文書を表示する際の書式を設定する必要があります。
次回は、XML文書の書式設定の概要および、電子ドキュメントとしての書式設定について学習します。
2009/04/07: 作成